GetBatch API: faster data retrieval for ML workloads
ML training and inference typically operate on batches of samples or data items. To simplify such workflows, AIStore 4.0 introduces the GetBatch API.
The API returns a single ordered archive - TAR by default - containing the requested objects and/or sharded files.
A given GetBatch may specify any number of items and span any number of buckets.
From the caller’s perspective, each request behaves like a regular synchronous GET, but you can read multiple batches in parallel.
Inputs may mix plain objects with any of the four supported shard formats (.tar, .tgz/.tar.gz, .tar.lz4, .zip), and outputs can use the same formats (default: TAR).
Ordering is strict: ask for data items named A, B, C - and the resulting batch will contain A, then B, then C.
Items A, B, C, etc. can reference plain objects or sharded files, stored locally or in remote cloud buckets.
Two delivery modes are available. The streaming path starts sending as the resulting payload is assembled. The multipart path returns two parts: a small JSON header (apc.MossOut) with per-item status and sizes, followed by the archive payload.
Get-Batch provides the largest gains for small-to-medium object sizes, where it effectively amortizes TCP and connection-setup overheads across multiple requests. For larger objects, overall performance improvement tapers off because the data transfer time dominates total latency, making the per-request network overhead negligible in comparison.
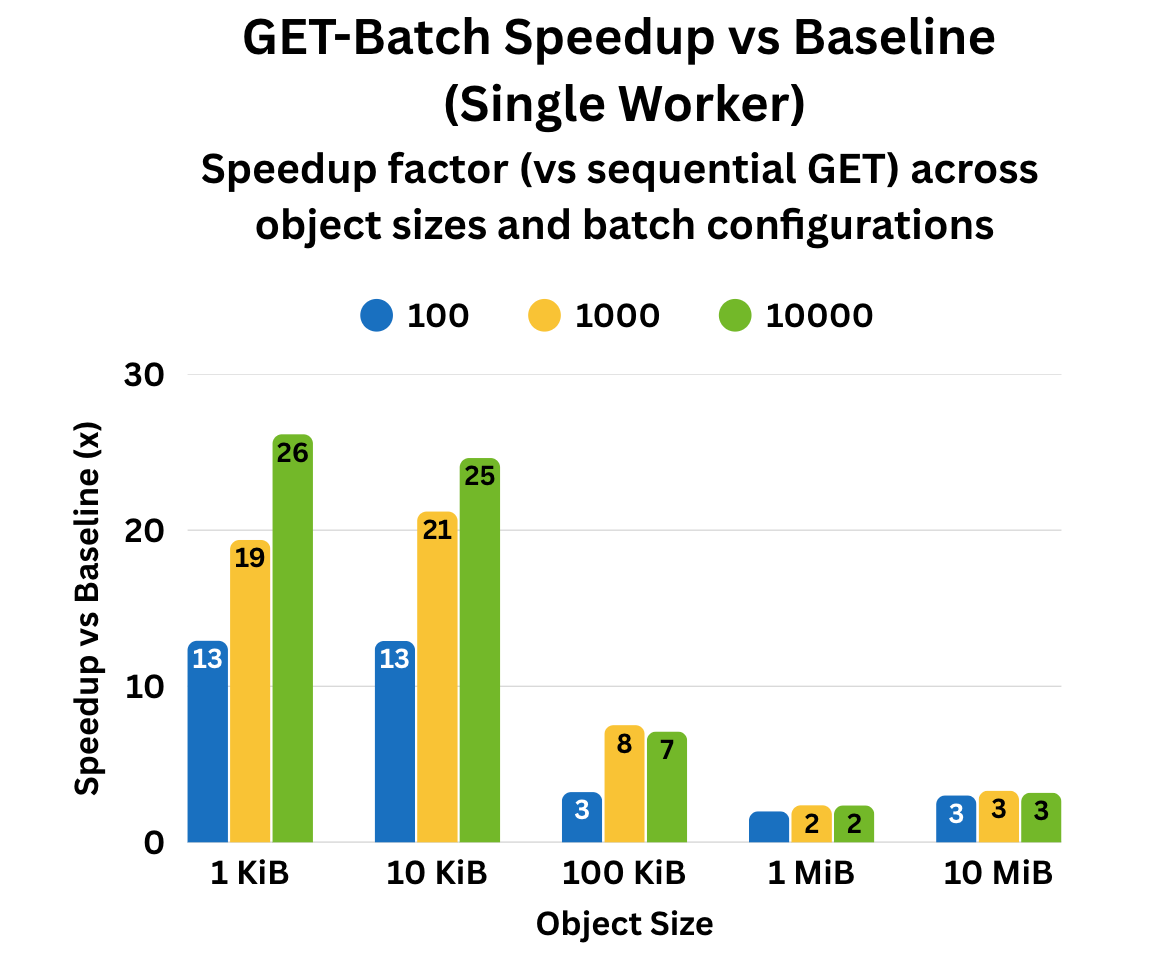
Fig. 1. Up to 25x single-worker speed-up in early benchmarks.
The graph plots speed-up factor (Y-axis) against object size (X-axis), showing how batch size (100, 1K, 10K objects per batch) and object size affect performance. Each test used 10k objects on a 3-node AIStore cluster (48 CPUs, 187 GiB RAM, 10×9.1 TiB disks per node). The gains come from reducing per-request TCP overhead and parallelizing object fetches.
PS. Cluster-wide multi-worker benchmarks are in progress and will be shared soon.