AIStore v3.28: Boost ETL Performance with Optimized Data Movement and Specialized Web Server Framework
The current state of the art involves executing data pre-processing, augmentation, and a wide variety of custom ETL workflows on individual client machines. This approach lacks scalability and often results in significant performance degradation due to unnecessary data movement. Unlike most open-source and cloud ETL solutions, AIStore performs transformations on the same machines that store your data, minimizing redundant transfers by exploiting data locality.
This is precisely why we developed an ETL subsystem for AIStore. As a distributed storage system, AIStore has precise knowledge of where every object resides within your dataset. This awareness eliminates redundant data movement, streamlining the entire pipeline and delivering, as we demonstrate below, a 35x speedup compared to conventional client-side ETL workflows.
This post highlights recent performance improvements across all three ETL stages in AIStore:
- Extract: Introduced WebSocket streaming communication mechanism between AIStore and the ETL web server.
- Transform: Provided a high-performance SDK framework to build ETL web server with custom transformation logic.
- Load: Enabled direct put, allowing ETL output to bypass intermediaries and write directly to the target node.
WebSocket Streaming: Persistent and Reusable Communication Channel
In distributed systems, the choice of communication protocol can significantly impact performance. In AIStore ETL (AIS ETL), the existing mechanisms (Hpush, Hpull, and I/O) rely on RESTful HTTP interfaces to transfer user data in HTTP requests and responses. While this approach provides clean isolation between the TCP sessions used for each individual object, it also introduces overhead: each object transformation requires to establish a new HTTP session, which can be costly, especially for small objects.
To reduce this overhead, AIStore ETL now supports a new communication type: WebSocket.
WebSocket enables long-lived TCP connections that facilitate continuous data streaming between targets and ETL containers without repeatedly setting up and tearing down. In contrast, HTTP-based traffic involves repeated connection establishment and termination with an overhead that grows inversely proportionally to the transfer sizes”
Specifically, for each offline (bucket-to-bucket) transform request, AIStore:
- Pre-establishes multiple long-lived WebSocket connections to the ETL server.
- Distributes source objects across these connections.
- Streams transformed object bytes back through the same connection.
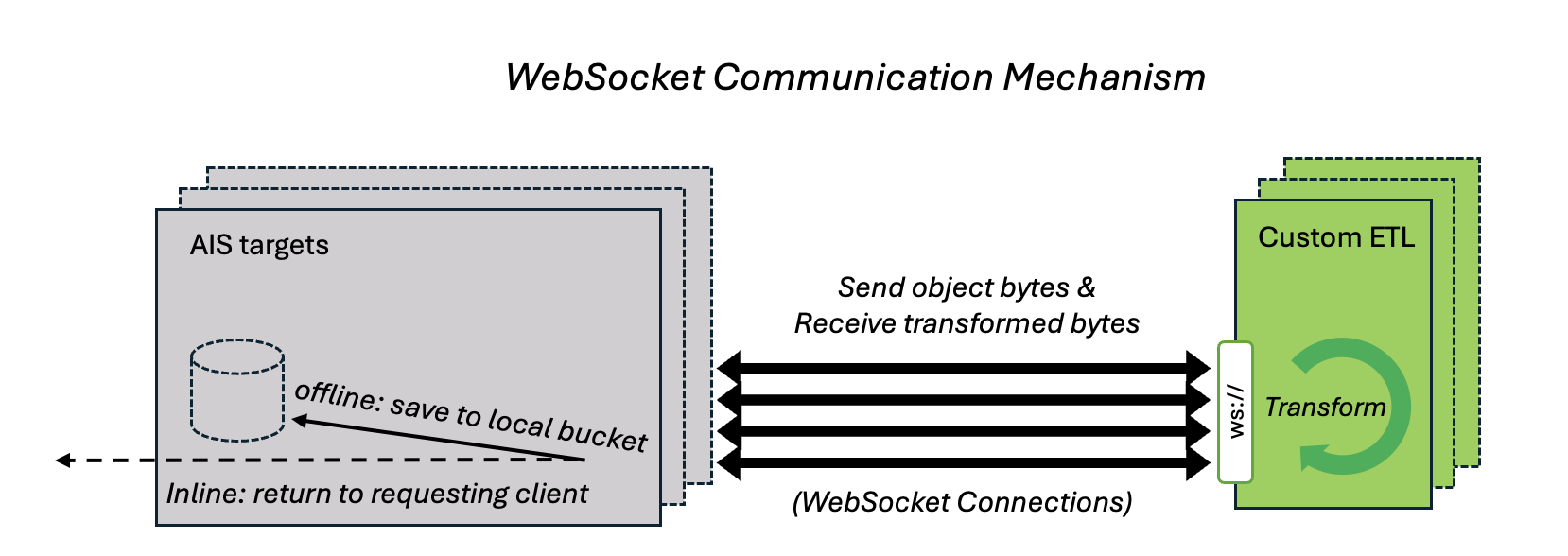
Note: With direct put optimization enabled, the transformed object is delivered to the destination target via an HTTP PUT request instead of being streamed back over the WebSocket connection.
This upgrade significantly reduces overhead and improves throughput, especially in high-volume transformations involving small-sized objects.
High-Performance ETL Web Server Framework
AIStore ETL is language- and framework-agnostic. You can deploy your own custom web server as a transformation pod, supporting both inline transformations (real-time GET requests) and offline batch transformations (bucket-to-bucket).
However, building such a server from scratch involves more than just writing transformation logic. It must also be capable of:
- Performing health checks
- Communicating with AIStore targets
- Parsing
etl args—user-defined parameters that control the transformation behavior - Supporting
direct put, which allows transformed objects to be directly written to the target bucket without going through the client - Managing HTTP and WebSocket protocols with proper concurrency control
Selecting the right web server and communication strategy depends on factors like object size and volume, desired concurrency model, and whether you need a synchronous (WSGI) or asynchronous (ASGI) stack. Each option has its own trade-offs.
To simplify this, we’ve introduced AIS-ETL Web Server Framework in both Go and Python. These SDKs abstract away the boilerplate—so you can build and deploy custom ETL containers in minutes. Focus solely on your transformation logic; the SDK handles everything else, including networking, protocol handling, and high-throughput optimizations.
Getting Started
Ready to build your own ETL server? Check out our quickstart guides and example implementations:
- Python SDK Quickstart (FastAPI, Flask, HTTP Multi-threaded)
- Go Web Server Framework Guide
-
Examples: Python Go
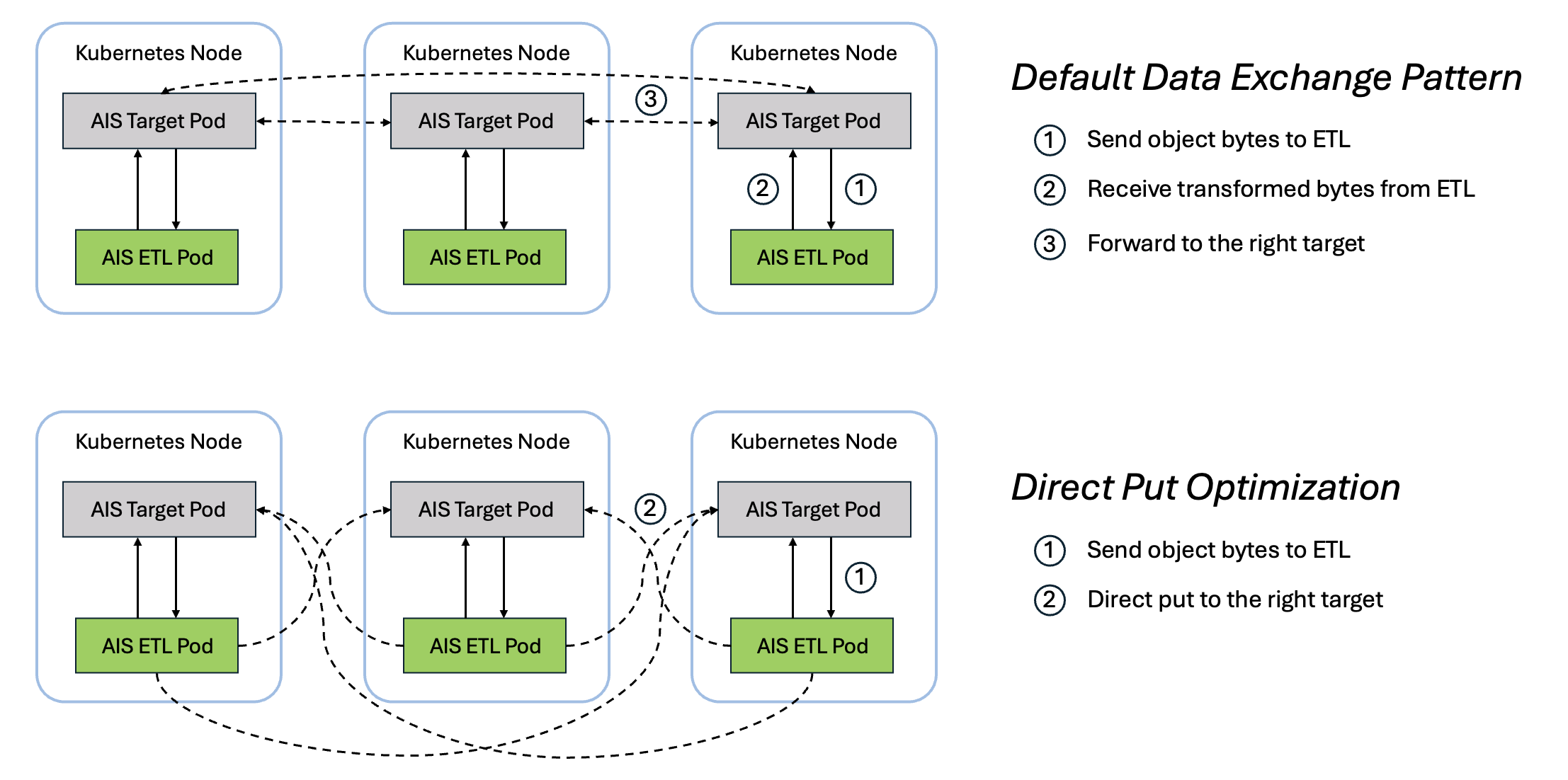
Direct Put Optimization: Faster Bucket-to-Bucket ETL Transformation
In offline transformations, the destination target for a transformed object usually differs from the original target. By default, the ETL container sends the transformed data back to the original source target, which then forwards it to the destination. The direct put optimization streamlines this flow by allowing the ETL container to send the transformed object directly to the destination target.
Benchmark: FFmpeg Audio Transformation
Now that we’ve introduced the ETL server framework, direct put optimization and websocket streaming, the next logical step is to see how they actually perform in a real-world scenario.
To evaluate AIStore’s ETL throughput, scalability, and impact of features like direct_put, we designed a benchmark using FFmpeg—a popular open-source tool for audio and video processing. This benchmark simulates a practical workload and helps highlight how different implementation choices affect performance.
The transformation pipeline converts .flac files to .wav, with tunable parameters for Audio Channels (AC) and Audio Rate (AR).
Why FFmpeg?
- Practicality – FFmpeg is widely adopted, including within NVIDIA’s own speech teams.
- Relevance – Audio transformation is a byte-level, compute-intensive task, ideal for end-to-end ETL benchmarking.
To expose FFmpeg as a transformation service, we used three different Python-based web servers—FastAPI, Flask, and a multi-threaded HTTP server. Each implementation was tested under multiple configurations, toggling direct_put (to control upload paths) and fqn (to apply fully qualified object naming).
1. Setup and Configuration
To ensure the benchmark reflects production-like conditions, we ran all tests on a high-performance Kubernetes cluster with ample CPU, memory, and storage capacity.
1.1. System Specs
The benchmark was run on a high-performance AIStore cluster using the following system configuration:
- Kubernetes Cluster: 3 bare-metal nodes, each hosting one proxy and one target
- Storage: 10 × 9.1 TiB HDDs per target
- CPU: 48 cores per node
- Memory: 187 GiB per node
1.2. Transformer and Scripts
The transformer and benchmark were implemented using the following components from the AIS ETL repository:
1.3. Dataset
We used the LibriSpeech (500 Hours) dataset, which contains approximately 149,000 .flac audio files. Each file was converted to stereo at 44,100 Hz and saved as .wav.
2. Baseline: Client-Side Transformation
Before diving into AIStore-based benchmarks, it’s helpful to understand the baseline: how long would this transformation take using traditional methods?
In typical object storage workflows, data preprocessing happens on client machines—data is pulled, processed locally, then uploaded back. We replicated this using a client machine with specs identical to the cluster nodes and ran the transformation with 24 threads.
- Total time: 2 hours 15 minutes 6 seconds
- Local Benchmark Script
3. AIStore ETL Benchmarks
With the baseline in place, we turned to benchmarking server-side transformation using AIStore ETL. We tested all three web servers—FastAPI, Flask, and HTTP—across multiple combinations of:
- Communication protocols: HPUSH, HPULL, WebSocket
fqnenabled/disabled: Whether to fully qualify object namesdirect_putenabled/disabled: Whether the transformer directly writes back to the target bucket
Each configuration was measured for total transformation time.
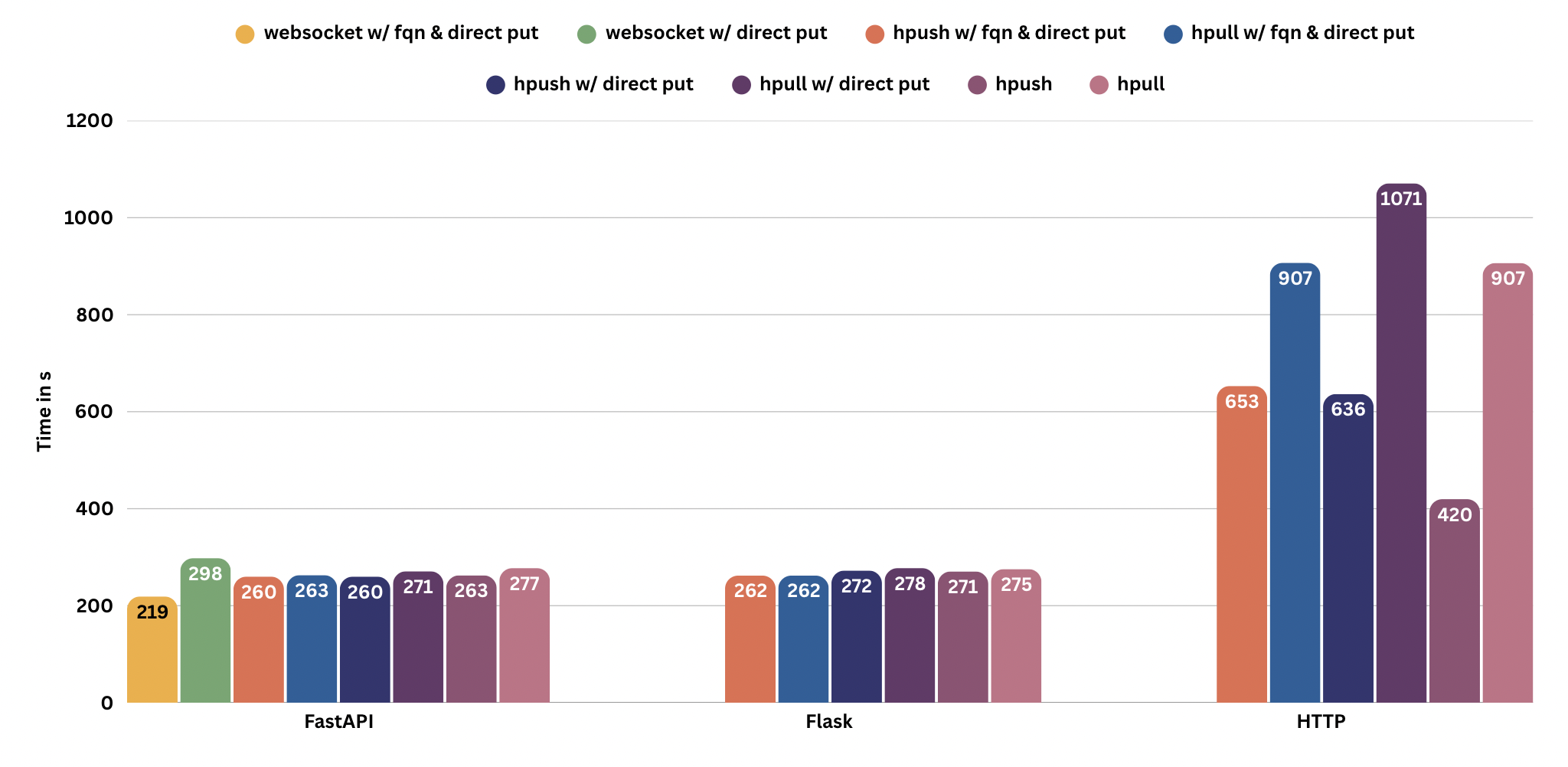
3.1. Results Summary
The following chart summarizes performance across the different configurations:
| Webserver | Communication Type | FQN | Direct Put | Seconds |
|---|---|---|---|---|
| fastapi | ws | fqn | True | 218.541 |
| flask | hpush | fqn | False | 258.171 |
| flask | hpull | fqn | False | 258.868 |
| fastapi | hpush | True | 259.963 | |
| fastapi | hpush | fqn | True | 260.094 |
| flask | hpull | fqn | True | 261.366 |
| flask | hpush | fqn | True | 261.658 |
| fastapi | hpush | False | 262.539 | |
| fastapi | hpull | fqn | True | 262.666 |
| fastapi | hpull | fqn | False | 263.526 |
| fastapi | hpush | fqn | False | 266.175 |
| flask | hpush | False | 270.632 | |
| fastapi | hpull | True | 270.923 | |
| flask | hpush | True | 272.426 | |
| flask | hpull | False | 275.475 | |
| fastapi | hpull | False | 277.491 | |
| flask | hpull | True | 277.512 | |
| fastapi | ws | fqn | True | 298.657 |
| http | hpush | False | 419.697 | |
| http | hpull | fqn | False | 441.644 |
| http | hpush | fqn | False | 444.687 |
| http | hpush | True | 636.434 | |
| http | hpush | fqn | True | 652.89 |
| http | hpull | False | 906.59 | |
| http | hpull | True | 1070.84 |
4. Performance Insights
The best-performing configuration—FastAPI using WebSocket, with fqn and direct_put enabled—completed the entire job in just 3 minutes 39 seconds.
This marks a ~35× speedup compared to the client-side baseline, where the same workload took over 2 hours to finish.
⚠️ Caveat: The baseline was run on a single client machine, while the AIStore benchmark used a 3-node cluster. This is not a 1:1 hardware comparison—but that’s exactly the point. AIStore ETL is built to scale horizontally. Client-side processing, even on powerful machines, hits I/O and CPU limits quickly. In contrast, AIStore parallelizes the workload across all available nodes.
Beyond raw speed, AIStore ETL eliminates unnecessary data movement, reduces client-side compute costs, and simplifies pipeline management. As the cluster size grows, performance scales linearly with added nodes/disks, offering even greater throughput potential.