Resilient Data Loading with ObjectFile
Massively parallel loading of terabytes of data in a distributed system presents reliability challenges. This holds true even for data centers where network stability is supposed to be stellar. Consider multi-node training of a model with (hundreds of) billions of parameters — a process that takes many hours, sometimes days. A single spurious interruption of any kind may disrupt workflows, forcing one of the compute workers to fail, ultimately leading to wasted time and resources.
Introduced in AIStore Python SDK version 1.8, ObjectFile supports local file-like semantics and efficiently handles interrupted streams.
Usage
ObjectFile is straightforward to use in the AIStore Python SDK. You can create a file-like object and read from it just as you would with any other file object:
import urllib3
from aistore.sdk.client import Client
# Customize the retry behavior for the initial connection
# status_forcelist enables retries on error codes we might get from a disconnected AIS target
retry = urllib3.Retry(total=3, status_forcelist=[400, 404])
client = Client("http://localhost:8080", retry=retry)
# Get a reference to the object
obj = client.bucket(BUCKET_NAME).object(OBJECT_NAME)
# Open the object as a file and read data in chunks
with obj.get_reader().as_file(max_resume=5) as file:
file.read(1024) # Read the first 1KB
file.read(1024) # Read the next 1KB
file.read() # Or read until EOF
During each read operation, ObjectFile will attempt to resume a disconnected stream up to 5 times in the above example. On each attempt to resume, the client will use the retry logic configured with the provided urllib3.Retry object.
See the AIS Python docs for a full example.
Background
The basic object.get_reader() function in the AIS SDK returns an ObjectReader, which enables efficient streaming of data by providing an iterator that fetches data in chunks (using the requests library’s stream option). However, it doesn’t account for network interruptions, such as unexpected stream closures or timeouts. In the case of a failure, the entire stream may need to be manually restarted, resulting in major inefficiencies and redundant data transfer.
ObjectFile addresses this problem by wrapping ObjectReader with a file-like interface that incorporates buffer management and logic to handle unexpected interruptions to the object stream. By resuming streams from the exact byte where an interruption occurred, ObjectFile eliminates the need to re-fetch previously read data, ensuring uninterrupted data access even in unstable network conditions.
With the usage and problem context in mind, the upcoming sections will explore:
- How
ObjectFileWorks: Delving intoObjectFile’s mechanics, such as buffer management and retry logic. - Integrating
ObjectFilein File-like Contexts: HowObjectFilefits into common libraries liketarfileandcsv. - Future Work: Ongoing efforts for improvements, including custom buffer sizes and parallel pre-fetching, along with benchmarking.
How ObjectFile Works
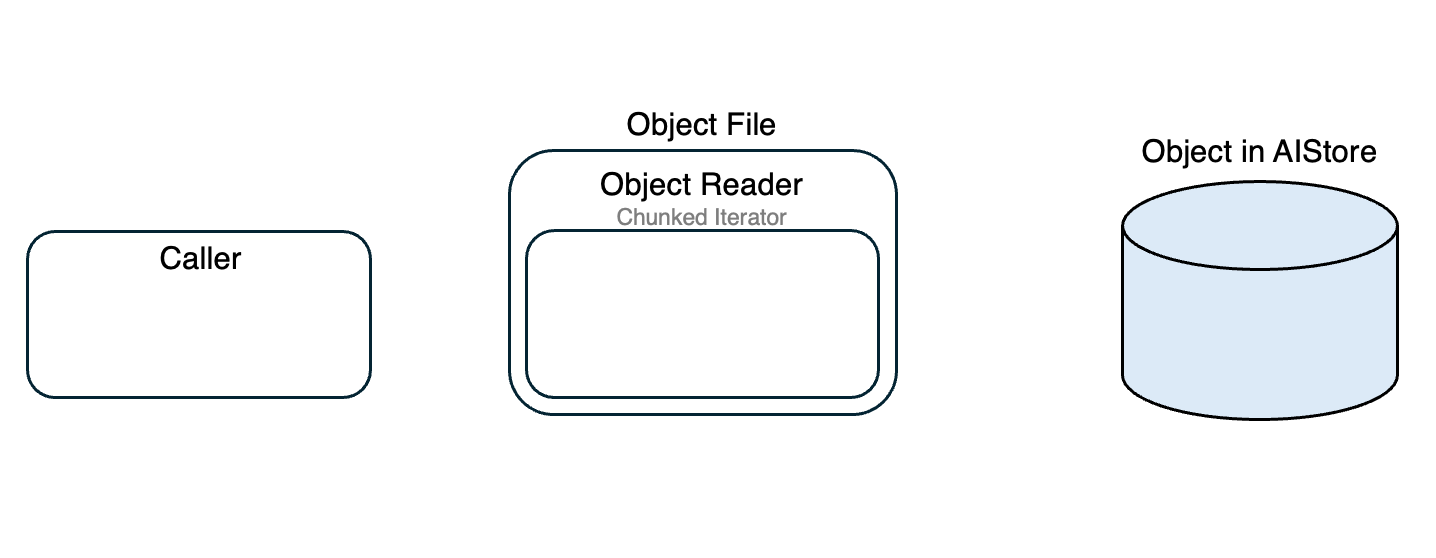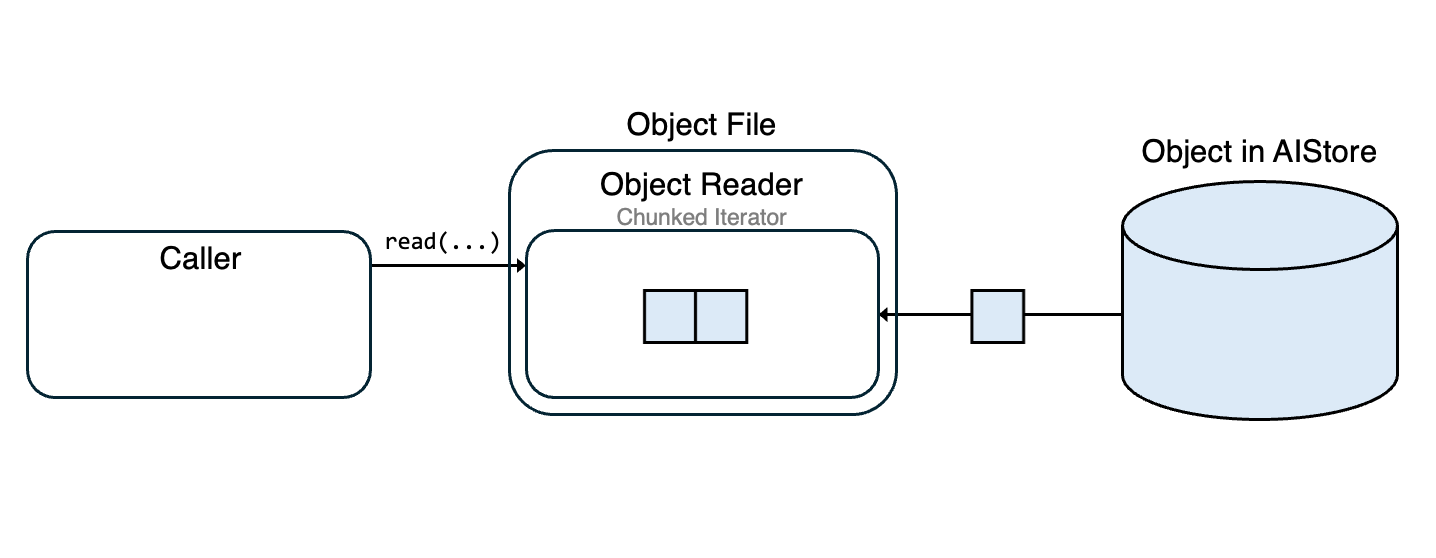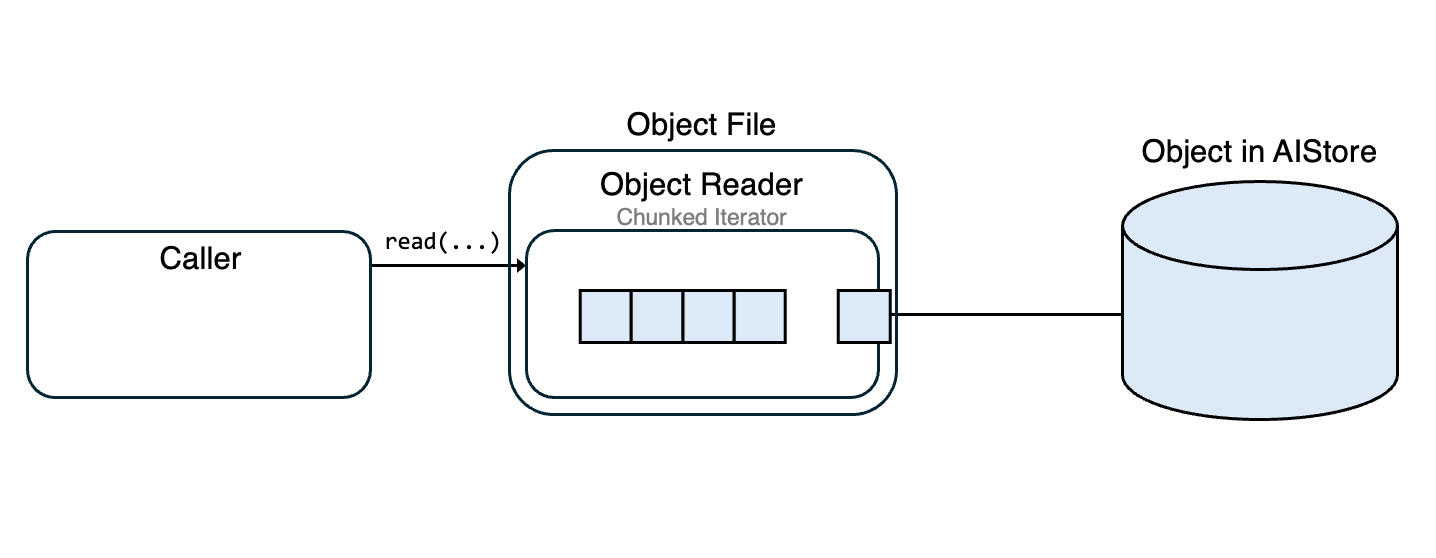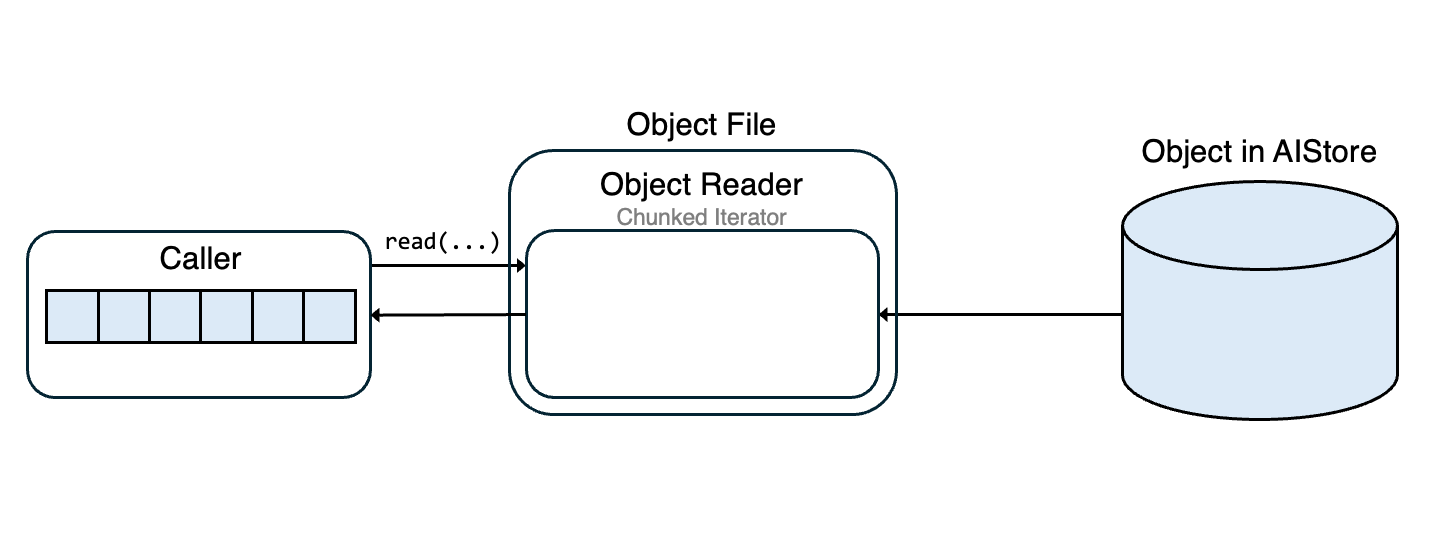
ObjectFile extends io.BufferedIOBase, offering a familiar file-like interface for reading streamed objects in chunks and handling interruptions gracefully. It relies on ObjectReader to fetch object data in chunks and maintains an internal buffer to optimize reads.
When a read operation is initiated, ObjectFile first checks if the requested data is already in the buffer. If sufficient data is available, it reads directly from the buffer. If not, it fetches additional chunks from the object stream using the iterator and refills the buffer.
In case of unexpected stream interruptions (e.g. ChunkedEncodingError, ConnectionError) or timeouts (e.g. ReadTimeout), ObjectFile automatically attempts to re-establish the connection to the object in AIS. It does this by issuing an HTTP range request starting at the next byte that hasn’t yet been loaded into the buffer. This ensures that no previously accessed data is fetched again, and the stream resumes seamlessly from where it left off.
Once the buffer has sufficient data, ObjectFile reads directly from it to complete the read operation.

Integrating ObjectFile in File-like Contexts
Because ObjectFile extends io.BufferedIOBase, you can use it in any context where a non-seekable file-like object is expected. For instance, ObjectFile works seamlessly with libraries like tarfile (in streaming modes such as r|*, r|, r|gz, where the pipe | indicates sequential streaming of tar blocks) and csv, which rely on standard file objects for sequential reads:
# Stream and extract a tar file
with client.bucket(BUCKET_NAME).object(OBJECT_NAME).get_reader().as_file(max_resume=5) as file_obj:
with tarfile.open(fileobj=file_obj, mode='r|*') as tar:
for member in tar:
print(f"Extracting {member.name}")
tar.extract(member)
# Stream a CSV file and iterate through rows
with client.bucket(BUCKET_NAME).object(OBJECT_NAME).get_reader().as_file(max_resume=5) as obj_file:
csv_reader = csv.reader(obj_file)
for row in csv_reader:
print(row)
In both cases, the file_obj ensures that streaming continues smoothly, even in the event of interruptions. The max_resume parameter dictates how many times each read operation (called internally by libraries like csv, tarfile, or similar) is allowed to resume following an interruption.
Future Work
While ObjectFile brings substantial improvements in terms of resilience and performance in streaming environments, there are several avenues for further optimization and enhancements:
Custom Buffer Size
In the initial implementation, ObjectFile uses an internal buffer of the same size requested by the reader (on each call to read()). For reading larger chunk sizes over the network, we rely on the object.get_reader() chunk_size parameter, which can exceed the requested buffer size. With a larger chunk size, the buffer will often still hold enough data for multiple reads.
Adding support for custom buffer sizes would allow further performance optimization by separating the buffer size from the amount specified in each read call. More work still needs to be done to determine optimal sizes for read, buffer, and chunk iteration (see Benchmarking section below for ongoing efforts to fine-tune these sizes).
Read-Ahead Buffer with Parallelization
Implementing a read-ahead buffer that pre-fetches data in parallel would minimize latency between reads. This approach would better utilize network bandwidth and avoid blocking during larger data fetches.
Benchmarking
Further benchmarks are currently underway to:
- Ensure minimal performance degradation under normal conditions.
- Demonstrate faster recovery from interruptions using range requests.
- Fine-tune buffer and chunk sizes for optimal stability and performance.
These results, which will also help guide the tuning of custom buffer sizes, will be detailed in an upcoming follow-up blog.
Conclusion
Addressing intermittent spurious interruptions is critical for resilient data streaming, and ObjectFile is our specific approach to solving this issue. As mentioned above, further evaluation is needed to confirm its effectiveness in minimizing overhead and improving performance.
Easy integration with existing workflows and familiar file-like behavior makes ObjectFile a practical choice for managing stream interruptions without requiring major changes to existing workflows.