Initial Sharding of Machine Learning Datasets
Introduction
Over the past decade, and especially in the last 3-4 years, the size of AI datasets has grown significantly, often exceeding the combined capacity of block storage devices that can be attached to a single server machine.
Hence, distributed storage.
There are plenty of distributed-storage options to choose from. However, the choice may appear to be limited, at least in part, due to the following challenges:
- large ML dataset contains a mix of large files (images, video) and small files (e.g., image labels);
- training a model entails random access to the entirety of the (again) extremely large dataset that cannot be cached;
- due to the model’s complexity and its size, training itself takes many hours, sometimes days,
- which then leads to the motivation to reduce this time without compromising accuracy.
All of the above is a problem. Performance problem, to be precise, for any distributed storage solution that was not originally designed to address all of the above in the first place.
What’s in a shard?
In this article, we narrowly focus on one specific aspect that directly affects training performance: sharding.
In AIStore, sharding refers to serializing original files (images, labels, etc.) into .tar (or .tgz, .zip, .tar.lz4) formatted objects.
Further, an AIStore shard is an object that also abides by a certain convention that is often referred to as WebDataset format. Ultimately, WebDataset convention is a short way to express the idea that serialized shards must contain batches of samples that, when received, can be immediately distributed between computing workers - one batch at a time.
But we’ll talk more about WebDataset convention (or format) later in this text. Serialization itself, though, offers well-known benefits:
- if done right, iterable serialized formats enable purely sequential I/O operations, improving performance on local drives by 3x-10x compared to the random access to huge numbers of files, including small files;
- long-lived compute-to-storage connections established to transmit larger payloads reduce network overhead;
- all of the above, in combination, optimizes end-to-end request handling latency and overall system throughput.
In the context of machine learning, further advantages can be gained through sharding, particularly when working with large datasets that are several orders of magnitude greater than server’s RAM.
Finally, sharding facilitates efficient, bias eliminating, data shuffling: you can shuffle shard names globally and use a shuffle buffer on the client side to further ensure that training data is adequately randomized.
Background: serialized shards in machine learning
There’s a handful of popular serialization formats. Maybe the first one that comes to mind is Google’s TFRecord - the format that efficiently serializes structured data using Protocol Buffers.
There’s also some existing research that tries to compare the associated pros and cons - see for instance:
- Streaming Technologies and Serialization Protocols: Empirical Performance Analysis, at https://arxiv.org/abs/2407.13494
In AIStore, we decided to optimize for unstructured data which broadly includes images, video, audio, sensor-generated streams, logs, web pages, biometric data, and much more. In short, unstructured data was a big part of the motivation but not the entire motivation. The second part of the motivation, or rather self-imposed requirement, was open format - emphasis on open.
The same already mentioned TFRecord is tightly integrated with TensorFlow, limiting its broader applicability. On the other hand, .tar exists for about 45 years (since 1979), is absolutely ubiquitous, and absolutely open.
We strongly advocate using open, ubiquitous, widely-supported, and standard GNU serialization formats. Such as
.tar,.zip, and similar. In addition to optimized performance, you are also getting your original data archived, preserving both the (original) directory structure, names, and sizes - everything.
The rest of this text is organized as follows:
- AIStore sharding API and CLI
- Initial sharding of machine learning datasets
ishard: integration with machine learning workflow- Data loading benchmark
- AIStore
ishardvs. AIStoredsort: when to use what?
AIStore sharding API and CLI
Sharding becomes especially important when working with petascale datasets.
To support those sizes, AIStore not only scales linearly with each added storage node and data drive. We also recognize the critical importance of sharding and provide APIs to create, read, write, and list archives in various serialized formats.
In addition, there are integrated batch operations to run concurrent multi-object sharding: to create shards given arbitrary lists or ranges of objects in any AIStore-accessible bucket
whereby source (or input) objects are not necessarily present in-cluster.
For example, given a bucket that contains objects (foo, bar, and baz) we could use CLI to create our first .tar shard:
$ ais archive --help ## see help for options and inline usage examples
$ ais archive ais://src ais://dst/shard1.tar --list foo,bar,baz
$ ais archive ls ais://dst/shard1.tar
NAME SIZE
shard1.tar 31.00KiB
shard1.tar/foo 9.26KiB
shard1.tar/bar 9.26KiB
shard1.tar/baz 9.26KiB
Initial sharding of machine learning datasets
Goes without saying: original machine learning datasets can have arbitrary structures, including deeply nested directories, a massive number of small or large files, or task-dependent annotation files.
Despite all this, there is almost always a need to batch associated files that constitute computable samples together for immediate consumption by a model. For example, train/part1/toyota.jpeg and label/20240807/toyota.xml are training data and corresponding annotations that should be kept together in the same batch. While you could prevent splitting computable samples by manually selecting associated files and individually archiving each of them, this approach is definitely impractical when working on a large, petabyte-scale dataset containing billions of arbitrarily-structured files.
This is where ishard comes in.
Initial Sharding utility (ishard) is designed to create WebDataset-formatted shards from the original dataset without splitting computable samples. The ultimate goal is to allow users to treat AIStore as a vast data lake, where they can easily upload training data in its raw format, regardless of size and directory structure.
Next, use ishard to perform the sharding pre-process correctly and optimally. The only question users need to address boils down to: How should ishard associate samples with their corresponding annotations/labels?
In this article, we will demonstrate how simple it is to configure ishard to associate samples and how much the overall data loading performance is improved after sharding.
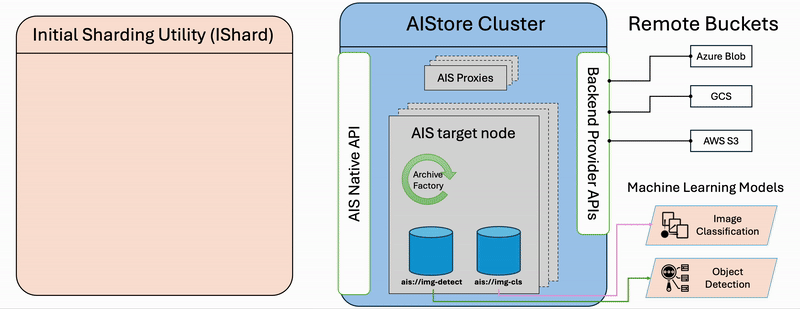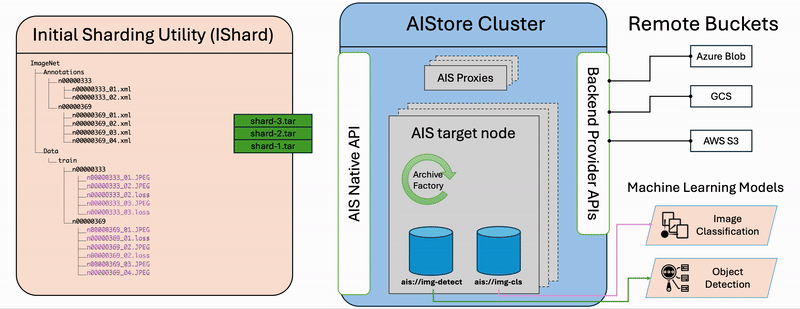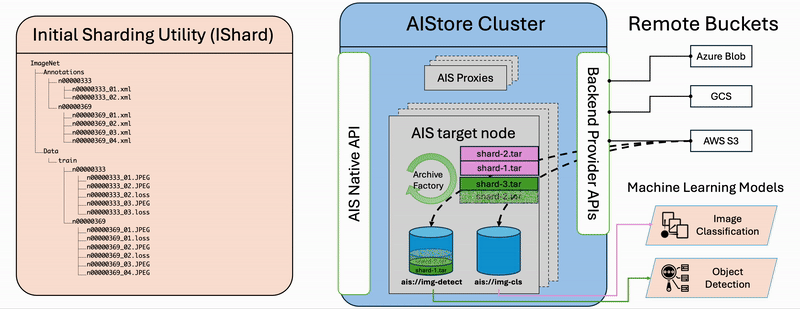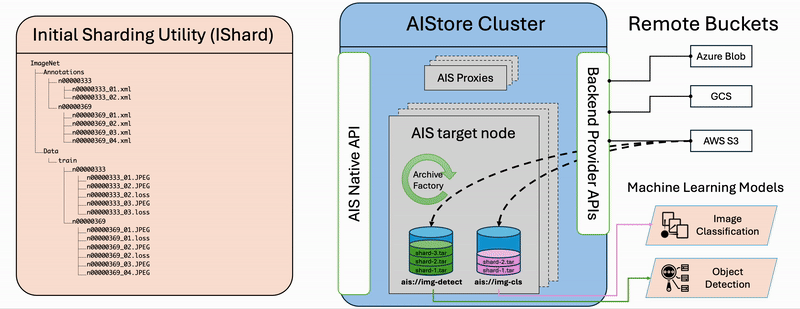
The diagram illustrates the step-by-step workflow of the ishard process:
- List Files: Retrieve all selected files from the source bucket.
- Group Samples: Associate files that constitute computable samples together according to the configured
sample_key_patternrule. - Create Shards: Collect samples until the configured
shard_sizeis reached, then request AIStore to asynchronously archive the collection into a shard.
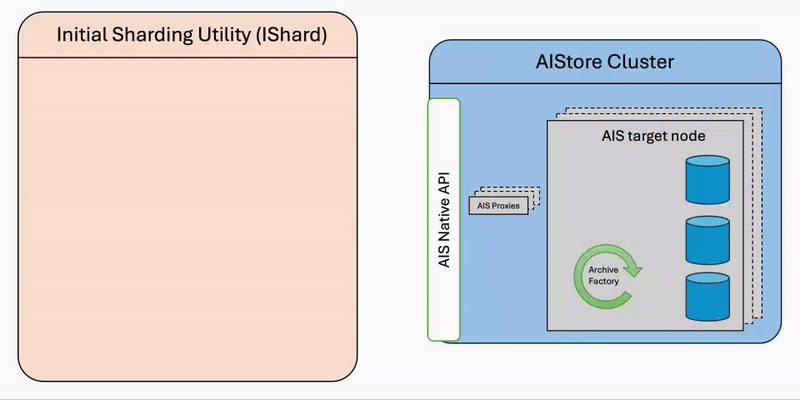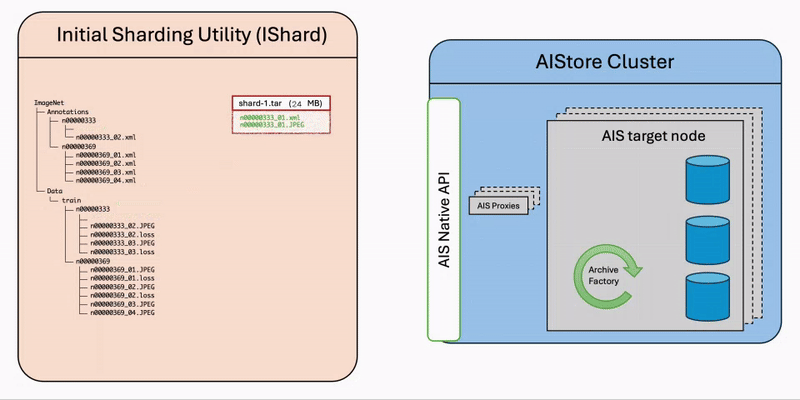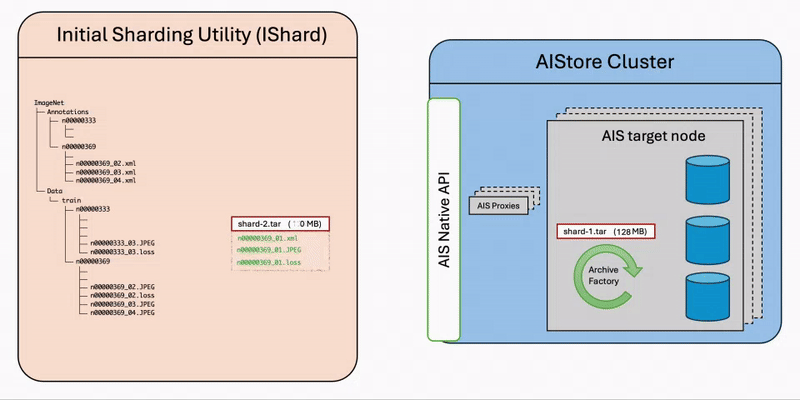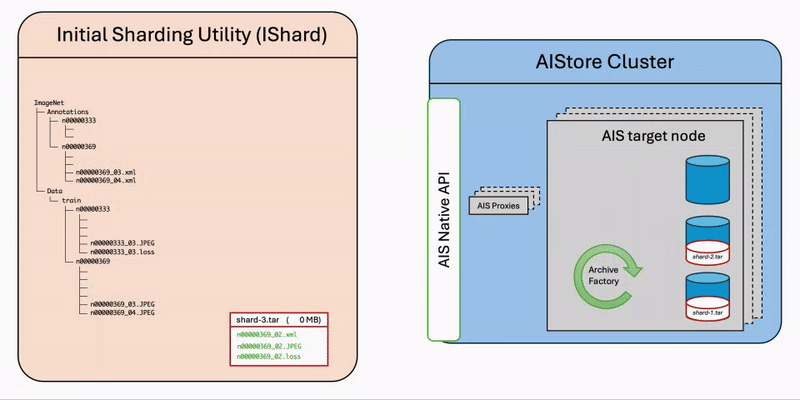
It’s important to note that ishard doesn’t alter the original dataset but instead transforms it into a new independent bucket. Specifically, ishard copies and shards a selected subset of data into an isolated workspace tailored for your specific ML task. This fully isolated on-demand approach ensures that ishard provides an exact, independent, and I/O performance-optimized working dataset for each individual ML task.
ishard: integration with machine learning workflow
In this post, we’ll demonstrate how to utilize ishard and AIStore’s PyTorch data loaders to efficiently work with the ImageNet dataset.
Prepare the original ImageNet dataset
First, use this script to download the ImageNet dataset. After downloading, you can inspect the resulting directory structure as follows.
tree $IMAGENET_HOME
.
├── annotation
│ ├── n00007846
│ │ └── Annotation
│ │ └── n00007846
│ │ ├── n00007846_103856.xml
│ │ ├── n00007846_104163.xml
│ │ └── ...
│ ├── n00015319
│ │ └── ...
│ └── ...
├── train
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
| │ └── ...
│ ├── n01443537
| | └── ...
│ └── ...
│
├── validation
│ └── val
│ ├── ILSVRC2010_val_00000001.JPEG
│ ├── ILSVRC2010_val_00000002.JPEG
| └── ...
...
Prepare buckets and upload the ImageNet dataset to AIStore.
$ ais bucket create ais://ImageNet ais://ImageNet-sharded
$ ais put "./" ais://ImageNet --recursive
Execute ishard
Install the latest version of the ishard executable.
$ go install github.com/NVIDIA/aistore/cmd/ishard@latest
Because sharding a large dataset can take hours to complete, it is highly recommended to first perform a
dry-runof yourishardcommand to ensure it produces the expected output shard composition.
Usage 1: extract only base filename as sample key
In most cases, training data and associated annotation files share the same base filename but have different extensions (e.g., n01440764_12957.JPEG for data and n01440764_12957.xml for annotations). By default, ishard recognizes files sharing the same base filename as an indivisible sample, ensuring they are included in the same shard.
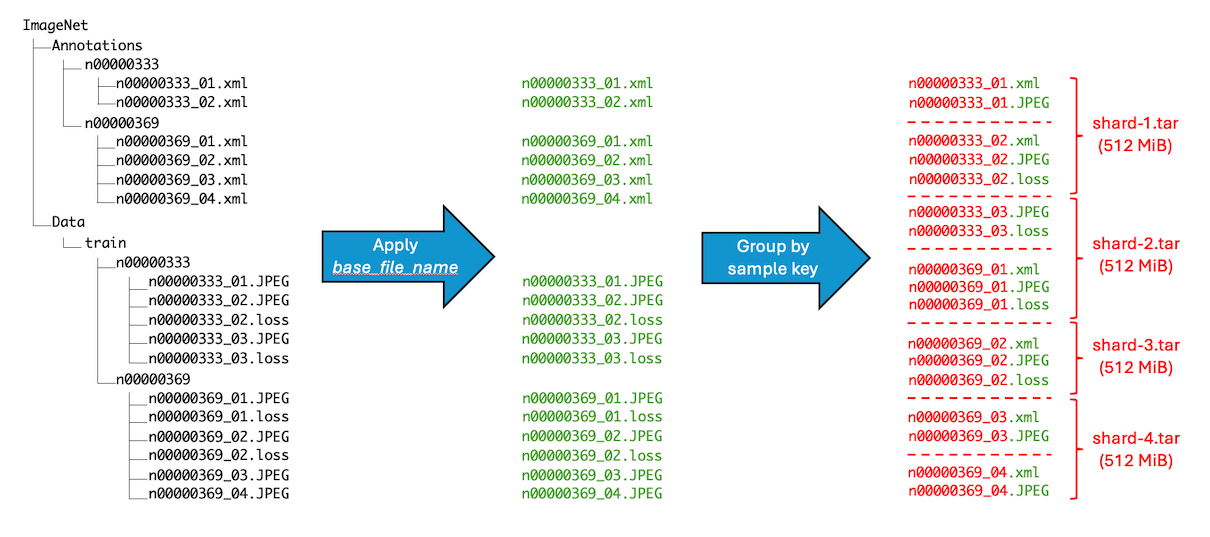
$ ishard -shard_size=512MiB -src_bck=ImageNet -dst_bck=ImageNet-sharded
shard-10.tar 512.01MiB
shard-10/train/n01440764/n01440764_12957.JPEG 131.09KiB
shard-10/train_annotation/n01440764/n01440764_12957.xml 709B
shard-10/train/n01440764/n01440764_12971.JPEG 58.81KiB
shard-10/train/n01440764/n01440764_12972.JPEG 164.68KiB
shard-10/train_annotation/n01440764/n01440764_12972.xml 484B
...
shard-11.tar 512.10MiB
...
As shown above, in the ImageNet dataset, some source image files do not have corresponding bounding box annotations .xml. For fully supervised tasks where annotation files are always needed for each training sample, you can specify sample_exts to include all desired extensions for each sample, and explicitly set missing_extension_action="exclude". This will enforce ishard to filter out incomplete samples.
# The created shards size is less than total source objects size, because incomplete samples are excluded
$ ishard -shard_size=512MiB -sample_exts=".JPEG,.xml" -missing_extension_action="exclude" -src_bck=ImageNet -dst_bck=ImageNet-sharded -progress
Source Objects: 148.36GiB
Created Shards Size: 61.3GiB / 62.3GiB [============================================================>-] 98% 11m49s
$ ais archive ls ais://ImageNet-sharded --limit=100
NAME SIZE
shard-000000.tar 517.74MiB
shard-000000/train/n01440764/n01440764_10040.JPEG 143.06KiB
shard-000000/train_annotation/n01440764/n01440764_10040.xml 483B
shard-000000/train/n01440764/n01440764_10048.JPEG 44.15KiB
shard-000000/train_annotation/n01440764/n01440764_10048.xml 483B
...
You can also specify -missing_extension_action="abort" to stop if any sample is missing a specified extension. ishard will correctly report which sample is missing which extension.
$ ishard -shard_size=512MiB -sample_exts=".JPEG,.xml" -missing_extension_action="abort" -src_bck=ImageNet -dst_bck=ImageNet-sharded -progress
Source Objects: 148.36GiB
ishard execution failed: sample n01484850.sbow contains extension .mat, not specified in `sample_ext` config
...
Usage 2: sharding by original directory structure
Sometimes, your dataset might already be hierarchically structured. For example, the ImageNet training dataset is categorized by synsets IDs (e.g., n0xxxxxxx) as directory names. These synset IDs correspond to specific labels in the dataset, such as the synset ID n01440764, which corresponds to the category “tench” (a type of fish). All images in the directory n01440764 are labeled as images of tench.
In this case, you can use the full_name sample key pattern and specify the prefix /train in the source bucket, indicating to ishard to only consider files in this directory. Then, ishard will reconstruct the original directory structure and peel off every subdirectory to form independent shards, from bottom to top.
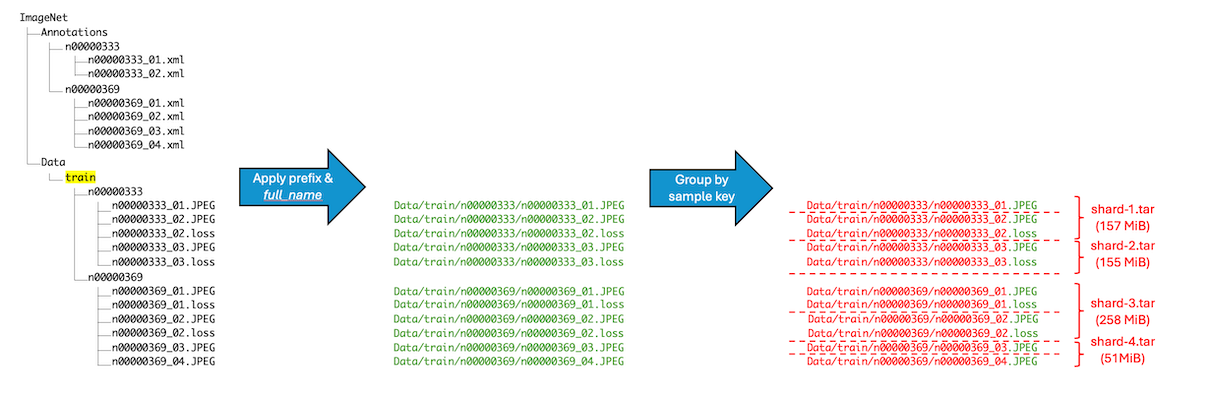
$ ishard -sample_key_pattern="full_name" -shard_size=512MiB -src_bck=ImageNet/train -dst_bck=ImageNet-sharded
$ ais archive ls ais://ImageNet-sharded --limit=100
shard-10.tar 157.60MiB
shard-10/train/n02097658/n02097658_10013.JPEG 15.18KiB
shard-10/train/n02097658/n02097658_10015.JPEG 120.11KiB
shard-10/train/n02097658/n02097658_10020.JPEG 29.57KiB
...
shard-11.tar 155.44MiB
shard-11/train/n03495258/n03495258_10028.JPEG 81.69KiB
shard-11/train/n03495258/n03495258_1003.JPEG 411.34KiB
...
You may notice that, although we configured shard_size=512MiB, none of the output shards actually reach this size. This is because, by default, ishard maintains clear boundaries between files that belong to different virtual directories, even if an output shard’s size doesn’t reach the requested shard_size.
To disable this default setting and compact each output shard’s size closer to shard_size, regardless of directories, you can specify the -collapse flag. This allows ishard to collapse samples into their parent directory if their overall size doesn’t reach shard_size.
$ ishard -sample_key_pattern="full_name" -collapse -shard_size=512MiB -src_bck=ImageNet/train -dst_bck=ImageNet-sharded
$ ais archive ls ais://ImageNet-sharded --limit=100
shard-9.tar 543.05MiB
...
shard-9/train/n01631663/n01631663_10036.JPEG 153.73KiB
shard-9/train/n01631663/n01631663_996.JPEG 245.67KiB
shard-9/train/n02965783/n02965783_10361.JPEG 78.58KiB
...
Usage 3: sharding by customized categories
In some cases, you may want to pack samples into shards based on customized categories. For example, with the ImageNet dataset, you may not need to classify images at a detailed level. Instead, you may want to treat both “tench” and “goldfish” as just “fish”. In such cases, you can use an external key map (EKM) to specify the exact mapping from samples to output shards.
If your desired sharding structure cannot be directly derived from the names of the source files using
sample_key_pattern, we suggest using EKM to specify your desired packing rules.
The following example EKM file will pack all samples matching these specified templates into their corresponding categories.
{
"fish-%d.tar": [
"train/n01440764.*", // tench
"train/n01443537.*", // goldfish
...
],
"dog-%d.tar": [
"train/n02084071.*", // toy terrier
"train/n02085782.*", // Japanese spaniel
"train/n02085936.*", // Maltese dog
...
],
"bird-%d.tar": [
"train/n01514668.*", // cock
"train/n01514859.*", // hen
...
],
}
To run ishard with the EKM file:
$ ishard -ekm="/path/to/category.json" -sample_key_pattern="base_name" -src_bck=ImageNet/train -dst_bck=ImageNet-sharded
$ ais archive ls ais://ImageNet-sharded --limit=100
NAME SIZE
bird-0.tar 1.08MiB
bird-0.tar/train/n01514668/n01514668_10004.JPEG 124.09KiB
...
bird-176.tar 1.06MiB
bird-176.tar/train/n01514668/n01514668_9964.JPEG 133.77KiB
bird-176.tar/train/n01514668/n01514668_9973.JPEG 95.13KiB
...
dog-0.tar 1.36MiB
dog-0.tar/train/n02085782/n02085782_1006.JPEG 1.01KiB
...
fish-0.tar 1.01MiB
fish-0.tar/train/n01440764/n01440764_10026.JPEG 13.38KiB
...
Data loading benchmark
We conducted a micro-benchmark to assess the impact of sharding on data loading performance by iterating over one epoch of a 150GB ImageNet dataset. We compared the results before and after applying ishard with different shard sizes.
Bench setup
- OS: Ubuntu 22.04.1 LTS
- CPUs: 16 cores
- Memory: 32GB
AIStore was deployed locally with the following setup using local playground deployment script:
$ ./scripts/clean_deploy.sh --target-cnt 3 --proxy-cnt 1 --mountpath-cnt 3
1. Loading from the original dataset
Below is the minimal code for using AISIterDataset to iterate through the original ImageNet dataset stored in ais://ImageNet:
client = Client(AIS_ENDPOINT)
dataset = AISIterDataset(ais_source_list=client.bucket("ais://ImageNet"))
loader = DataLoader(dataset, batch_size=256, num_workers=8)
start = timer()
for urls, data in loader: # iterate through the original `ais://ImageNet` dataset
for idx in range(len(urls)):
len(data[idx]) # Ensure the data content is read
elapsed_time = timer() - start
print(f"Time spent: {elapsed_time:.2f} seconds")
2. Loading from the sharded dataset
Here’s the minimal code for using AISShardReader to iterate through the sharded ImageNet dataset stored in ais://ImageNet-sharded:
client = Client(AIS_ENDPOINT)
shard_reader = AISShardReader(bucket_list=client.bucket("ais://ImageNet-sharded"))
loader = DataLoader(shard_reader, batch_size=256, num_workers=8)
start = timer()
for basenames, content_dict in loader: # iterate through the sharded `ais://ImageNet-sharded` dataset
for idx, basename in enumerate(basenames):
for k, v in content_dict.items():
if v[idx] != b"":
len(v[idx]) # Ensure the data content is read
elapsed_time = timer() - start
print(f"Time spent: {elapsed_time:.2f} seconds")
Performance comparison
| Shard Avg. Size | Not Sharded | 128 KiB | 256 KiB | 512 KiB | 2 MiB | 8 MiB | 32 MiB | 128 MiB | 512 MiB |
|---|---|---|---|---|---|---|---|---|---|
| Total Time Spent (sec) | 1184.40 | 959.13 | 682.74 | 476.34 | 348.27 | 369.88 | 407.16 | 528.28 | 598.07 |
| Total Throughput (MiB/s) | 128.27 | 158.39 | 222.52 | 318.93 | 436.22 | 410.73 | 373.12 | 287.57 | 254.02 |
| Throughput per Worker (MiB/s) | 16.03 | 19.80 | 27.82 | 39.86 | 54.53 | 51.34 | 46.64 | 35.95 | 31.75 |
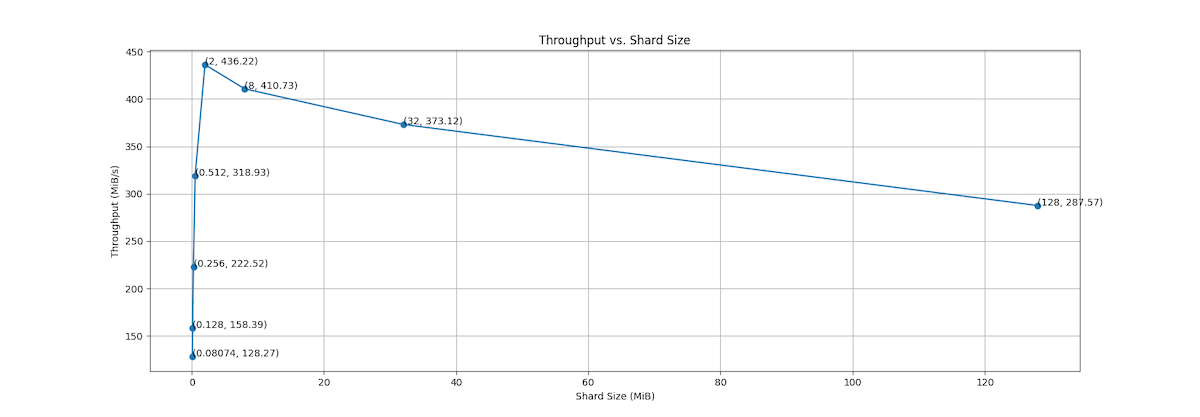
The benchmark reveals a significant improvement in data loading performance after sharding with ishard. The throughput increases dramatically, with the best performance observed at a shard size of 2 MiB, which delivers nearly 3.4 times the efficiency compared to the unsharded dataset. These findings underscore the importance of selecting an optimal shard size, as it effectively balances I/O efficiency with processing overhead, leading to the best possible data loading performance.
AIStore ishard vs. AIStore dsort: when to use what?
Both ishard and dsort are AIStore extensions designed for dataset sharding, but they serve different purposes at different stages of your workflow. ishard is intended to transform an initially flat-formatted dataset into a sharded format, whereas dsort is used for reorganizing an already-sharded dataset.
If your dataset is already in a sharded format and you need to reorganize the data within those shards, whether it’s adjusting shard size or reordering/re-shuffling data, you should directly use dsort with your desired configuration. However, if your dataset is not yet sharded, you’ll need to start with ishard to create the initial shards. You can then use dsort for further reorganization if needed. ishard also offers inline integration via the -sort flag, allowing you to directly execute dsort on the dataset immediately after ishard-ing it.
Conclusion
AIStore ishard is motivated by the idea to optimally serialize machine learning data consisting of a mix of large and small files. By serializing these original files into shards, ishard helps to remove performance bottlenecks almost ineviably associated with random read access and inefficient I/O operations in distributed storage environments.
Additionally, ishard offers flexible configuration options to manage arbitrarily structured datasets. It allows users to associate files that constitute computable samples, and group them into easily consumable shards.
Finally, the performance improvements demonstrated in our micro-benchmarks underscore the substantial benefits of using ishard for sharding large-scale datasets. This enhances overall data loading efficiency, making it a crucial tool for optimizing large scale machine learning pipelines.
Looking ahead, we plan to utilize ishard in a data center, in large AIStore cluster environments, to benchmark and compare (with and without sharding) performances of petacale datasets.