AIStore with WebDataset Part 2 -- Transforming WebDataset Shards in AIS
Note: This blog post references
init_codewhich has been removed and replaced withinit_class. For the most up-to-date ETL initialization methods, please refer to the init_class documentation.
In the previous post we converted a dataset to the WebDataset format and stored it in a bucket in AIStore.
This post will demonstrate AIStore’s ability to efficiently apply custom transformations to the dataset on the storage cluster. We’ll do this using AIS ETL.
All code used below can be found here: WebDataset ETL Example
Motivation for AIS ETL
AIS ETL takes advantage of processing power available on the storage cluster, as even an otherwise heavily utilized cluster will be idle, CPU-wise, over 90% of the time (of course, depending on specific workloads). Performing transformations close to the data maximizes efficiency and can reduce the amount of network traffic depending on the transforms applied. This makes it a much better option than pulling all the required data for training and doing both preprocessing and training on the same system.
In this demo, the ETL on AIStore is relatively lightweight, but offloading the pre-training computation to the AIS cluster could be much more important with a more intensive transform. For more advanced workloads such as audio or video transcoding or other computer-vision tasks, GPU-accelerated transformations may be desired. While it is beyond the scope of this article, such a setup can be achieved with the right hardware (e.g. Nvidia DGX), containers with GPU access (NVIDIA Container Toolkit), and the AIS init_spec option.
WebDataset-compatible Transforms
We start with a bucket in AIStore filled with objects where each object is a shard of multiple samples (the output of part 1). For our ETL to be able to operate on these objects, we need to write a function that can parse this WebDataset-formatted shard and perform the transform on each sample inside.
Below is a diagram and some simple example code for an ETL that parses these tar files and transforms all image files found inside (without creating any residual files). Since each object in AIS is a shard of multiple records, the first step is to load it from the URL as a WebDataset object. With this done, the WebDataset library makes it easy to iterate over each record, transform individual components, and then write out the result as a complete transformed shard.
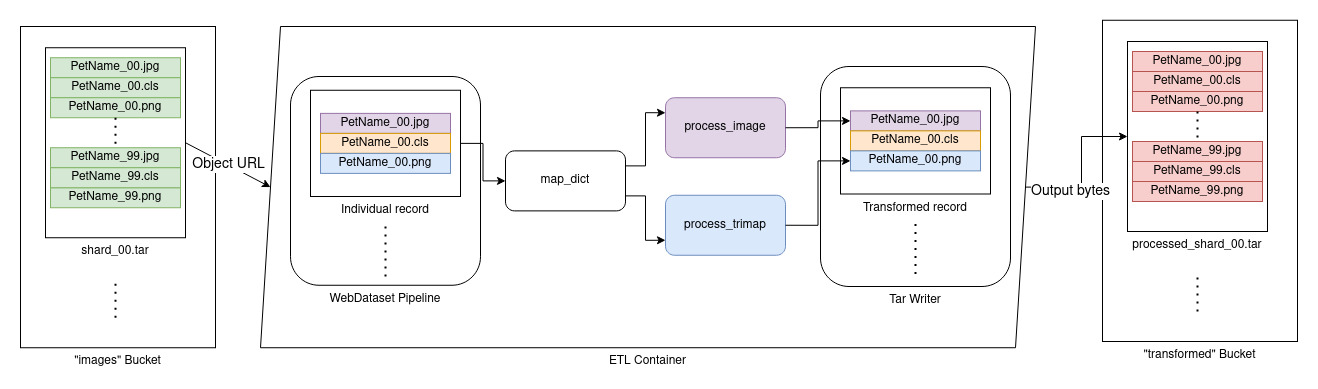
All functions must be included in the wd_etl function when using init_code as shown, since that is the code that is packaged and sent to run on the cluster in the ETL container. For more flexibility when defining the ETL container, check out the init_spec option.
def wd_etl(object_url):
def img_to_bytes(img):
buf = io.BytesIO()
img = img.convert("RGB")
img.save(buf, format="JPEG")
return buf.getvalue()
def process_trimap(trimap_bytes):
image = Image.open(io.BytesIO(trimap_bytes))
preprocessing = torchvision.transforms.Compose(
[
torchvision.transforms.CenterCrop(350),
torchvision.transforms.Lambda(img_to_bytes)
]
)
return preprocessing(image)
def process_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes)).convert("RGB")
preprocessing = torchvision.transforms.Compose(
[
torchvision.transforms.CenterCrop(350),
torchvision.transforms.ToTensor(),
# Means and stds from ImageNet
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
torchvision.transforms.ToPILImage(),
torchvision.transforms.Lambda(img_to_bytes),
]
)
return preprocessing(image)
# Initialize a WD object from the internal object URL in AIS
dataset = wds.WebDataset(object_url)
# Map the files for each individual sample to the appropriate processing function
processed_shard = dataset.map_dict(**{"image.jpg": process_image, "trimap.png": process_trimap})
# Write the output to a memory buffer and return the value
buffer = io.BytesIO()
with wds.TarWriter(fileobj=buffer) as dst:
for sample in processed_shard:
dst.write(sample)
return buffer.getvalue()
Now we must initialize the above function as an ETL process on the AIS cluster.
Notice the ETL defined above takes an object URL as input, so for this case we will need to use the hpull communication type along with the transform_url option. This allows us to initialize WebDataset (using its own reader) with the internal URL for the object. If transform_url is not set as True, the etl will default to sending the object bytes as the argument to the user-provided transform function.
Since both the WebDataset and PyTorch libraries try to import each other, we need to use the preimported_modules option to first import one before running the transform function:
def create_wd_etl(client):
client.etl(etl_name).init_code(
transform=wd_etl,
preimported_modules=["torch"],
dependencies=["webdataset", "pillow", "torch", "torchvision"],
communication_type="hpull",
transform_url=True
)
Transforming Objects
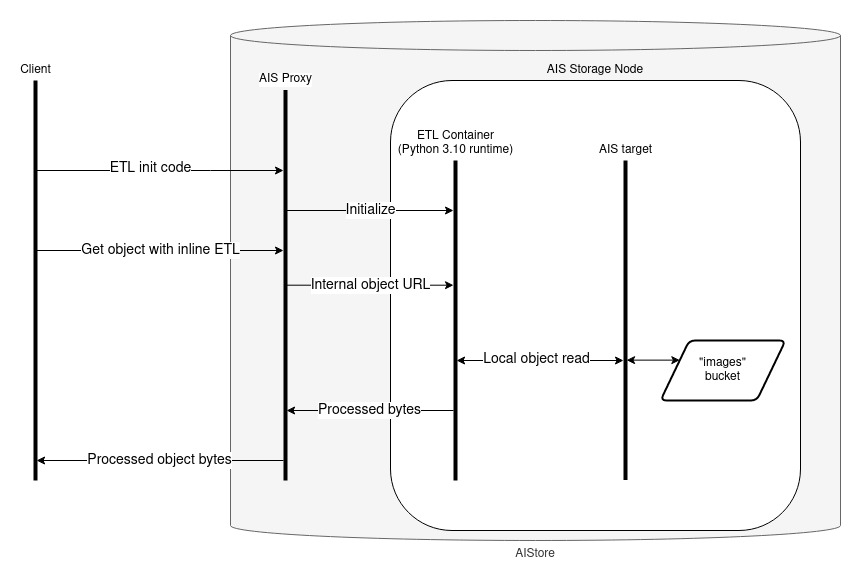
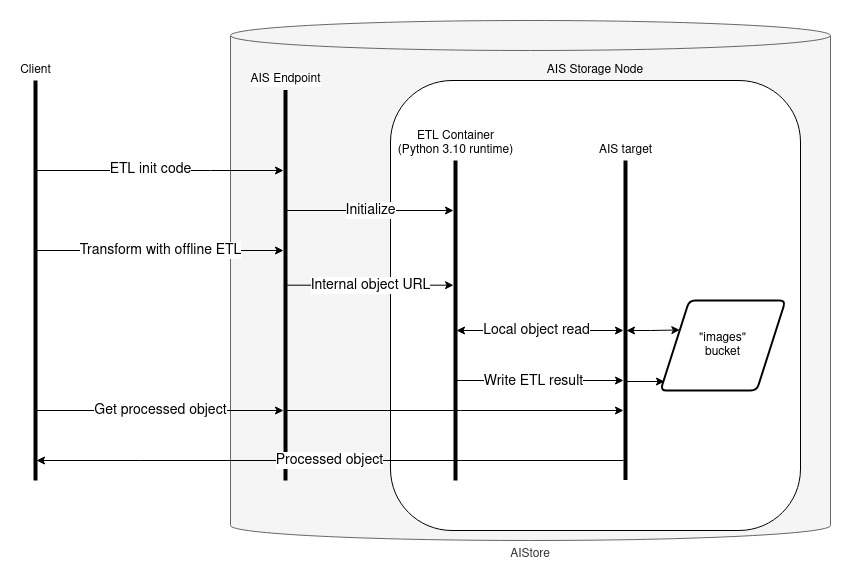
With the ETL created, we can use it to perform either an inline transformation to stream the results of a single object or an offline transformation to process objects within the cluster. The diagrams below are a simplified version of the full process (for more info on the inner workings, see here). The primary difference between the two approaches is simple: inline performs the transformation as part of the initial GET request, offline stores the results for a later request.
Inline (single object):
single_object = client.bucket(bucket_name).object("samples-00.tar")
# Get object contents with ETL applied
processed_shard = single_object.get_reader(etl_name=etl_name).read_all()
Offline (bucket-to-bucket):
dest_bucket = client.bucket("processed-samples").create(exist_ok=True)
# Transform the entire bucket, placing the output in the destination bucket
transform_job = client.bucket(bucket_name).transform(to_bck=dest_bucket, etl_name=etl_name)
client.job(transform_job).wait(verbose=True)
processed_shard = dest_bucket.object("samples-00.tar").get_reader().read_all()
Conclusion
This post demonstrates how to use WebDataset and AIS ETL to run custom transformations on the cluster, close to data. However, both offline and inline transformations have major drawbacks if you have a very large dataset on which to train. Offline transformations require far more storage than necessary as the entire output must be stored at once. Individual results from inline transformations can be inefficient to compute and difficult to shuffle and batch. PyTorch DataLoaders can help overcome this. In the next post, we’ll show how to put ETL to use when training a dataset by performing inline transformations on each object with a custom PyTorch Dataloader.
References
- GitHub:
- Documentation, blogs, videos:
- https://aiatscale.org
- https://github.com/NVIDIA/aistore/tree/main/docs
- AIStore with WebDataset Part 1 -- Storing WebDataset format in AIS
- Full code example
- Dataset
- PyTorch