MONITORING-PROMETHEUS
AIStore Observability: Prometheus
AIStore (AIS) exposes metrics in Prometheus format via HTTP endpoints. This integration enables comprehensive monitoring of AIS clusters, performance tracking, and trend analysis.
Table of Contents
- Overview
- Monitoring Architecture
- Prometheus Integration
- Node Alerts
- StatsD Alternative
- Best Practices
- References
- Related Documentation
Overview
AIS tracks a comprehensive set of performance metrics including:
- Performance counters
- Resource utilization percentages
- Latency and throughput metrics
- Data transfer statistics (total bytes and object counts)
- Error counters and operational status
Full observability is supported using multiple complementary tools:
- AIS node logs for detailed diagnostics
- CLI for interactive monitoring, specifically the
ais show cluster statscommand - Monitoring backends:
- Prometheus (recommended)
- StatsD with any compliant backend (e.g., Graphite/Grafana)
For information on load testing metrics, please refer to AIS Load Generator and How To Benchmark AIStore.
Monitoring Architecture
The typical monitoring setup with Prometheus looks as follows:
┌────────────────┐ ┌────────────────┐
│ │ scrape│ │
│ Prometheus │◄──────┤ AIStore Node │
│ │ │ /metrics │
└────────────────┘ └────────────────┘
│
│ query
▼
┌────────────────┐
│ │
│ Grafana │
│ │
└────────────────┘
This layout provides:
- Direct metric collection from AIS nodes
- Centralized metric storage in Prometheus
- Powerful visualization through Grafana dashboards
- Historical trend analysis and alerting capabilities
Prometheus Integration
Native Exporter
AIS is a fully compliant Prometheus exporter that natively supports metric collection without additional components. Key integration points:
- Configuration: No special configuration is required - simply build AIS without the
statsdbuild tag to enable Prometheus support - Metric Registration: When starting, each AIS node (gateway or storage target) automatically:
- Registers all metric descriptions (names, labels, and help text) with Prometheus
- Exposes the HTTP endpoint
/metricsfor Prometheus scraping
- Build Selection: The choice between StatsD and Prometheus is a build-time decision controlled by the
statsdbuild tag
For the complete list of supported build tags, please see conditional linkage.
Viewing Raw Metrics
You can directly view the exposed metrics using curl:
$ curl http://<aistore-node-ip-or-hostname>:<port>/metrics
# For HTTPS deployments:
$ curl https://<aistore-node-ip-or-hostname>:<port>/metrics
Sample output:
# HELP ais_target_disk_avg_rsize average read size (bytes)
# TYPE ais_target_disk_avg_rsize gauge
ais_target_disk_avg_rsize{disk="nvme0n1",node_id="ClCt8081"} 4096
# HELP ais_target_disk_avg_wsize average write size (bytes)
# TYPE ais_target_disk_avg_wsize gauge
ais_target_disk_avg_wsize{disk="nvme0n1",node_id="ClCt8081"} 260130
# HELP ais_target_disk_read_mbps read bandwidth (MB/s)
# TYPE ais_target_put_bytes counter
...
ais_target_put_bytes{node_id="ClCt8081"} 1.721761792e+10
# HELP ais_target_put_count total number of executed PUT(object) requests
# TYPE ais_target_put_count counter
ais_target_put_count{node_id="ClCt8081"} 1642
# HELP ais_target_put_ns_total PUT: total cumulative time (nanoseconds)
# TYPE ais_target_put_ns_total counter
ais_target_put_ns_total{node_id="ClCt8081"} 9.44367232e+09
# TYPE ais_target_state_flags gauge
ais_target_state_flags{node_id="ClCt8081"} 6
# HELP ais_target_uptime this node's uptime since its startup (seconds)
# TYPE ais_target_uptime gauge
ais_target_uptime{node_id="ClCt8081"} 210
...
For continuous monitoring of specific metrics without a full Prometheus deployment:
for i in {1..99999}; do
curl http://hostname:8081/metrics --silent | grep "ais_target_get_n.*node"
sleep 1
done
Key Metrics Groups
| Category | Metrics Prefix | Examples | Usage |
|---|---|---|---|
| Operations | ais_target_get_*, ais_target_put_* |
ais_target_get_count, ais_target_put_bytes |
Track throughput, operation counts |
| Resources | ais_target_disk_*, ais_target_mem_* |
ais_target_disk_util, ais_target_mem_used |
Monitor resource consumption |
| Errors | ais_target_err_* |
ais_target_err_get_count |
Track operation failures |
| Cloud operations | ais_target_cloud_* |
ais_target_cloud_get_count |
Monitor cloud backend activity |
| System | ais_target_uptime, ais_target_rebalance_* |
ais_target_uptime, ais_target_rebalance_objects |
System status, rebalancing |
Metric Labels
AIS exposes labels for detailed filtering and aggregation:
| Label | Description | Type |
|---|---|---|
node_id |
Unique node identifier | Static |
disk |
Disk identifier for storage metrics | Variable |
bucket |
Bucket name | Variable |
xaction |
Extended action (batch job) identifier | Variable |
Variable labels provide powerful filtering capabilities only available in Prometheus mode.
Essential Prometheus Queries
Here are key PromQL queries for operational monitoring:
# Cluster-wide GET operations per second (rate over 5m)
sum(rate(ais_target_get_count[5m]))
# Average GET latency in milliseconds
sum(rate(ais_target_get_ns_total[5m])) / sum(rate(ais_target_get_count[5m])) / 1000000
# Disk utilization per target
ais_target_disk_util{disk="nvme0n1"}
# Error rate as percentage of operations
sum(rate(ais_target_err_get_count[5m])) / sum(rate(ais_target_get_count[5m])) * 100
# Cluster storage capacity utilization
sum(ais_target_capacity_used) / sum(ais_target_capacity_total) * 100
# Node health status (state flags)
ais_target_state_flags
Node Alerts
AIStore node states are categorized into three severity levels:
- Red Alerts - Critical issues requiring immediate attention:
OOS- Out of space conditionOOM- Out of memory conditionOOCPU- Out of CPU resourcesDiskFault- Disk failures detectedNoMountpaths- No available mountpathsNumGoroutines- Excessive number of goroutinesCertificateExpired- TLS certificate has expiredCertificateInvalid- TLS certificate is invalid
- Warning Alerts - Potential issues that may require attention:
Rebalancing- Rebalance operation in progressRebalanceInterrupted- Rebalance was interruptedResilvering- Resilvering operation in progressResilverInterrupted- Resilver was interruptedNodeRestarted- Node was restarted (powercycle, crash)MaintenanceMode- Node is in maintenance modeLowCapacity- Low storage capacity (OOS possible soon)LowMemory- Low memory condition (OOM possible soon)LowCPU- Low CPU availabilityCertWillSoonExpire- TLS certificate will expire soonKeepAliveErrors- Recent keep-alive errors detected
- Information States - Normal operational states:
ClusterStarted- Cluster has started (primary) or node has joined clusterNodeStarted- Node has started (may not have joined cluster yet)VoteInProgress- Voting process is in progress
Node state flags are exposed via the Prometheus metric ais_target_state_flags and can be monitored using the following methods:
CLI Monitoring
The node state can be viewed directly using the CLI:
$ ais show cluster
This command displays the state for all nodes in the cluster, including any active alerts.
Prometheus Queries
To monitor node states with Prometheus:
# Detect nodes with any red alert condition
ais_target_state_flags > 0 and on (node_id) (
ais_target_state_flags & 8192 > 0 or # OOS
ais_target_state_flags & 16384 > 0 or # OOM
ais_target_state_flags & 262144 > 0 or # OOCPU
ais_target_state_flags & 65536 > 0 or # DiskFault
ais_target_state_flags & 131072 > 0 or # NoMountpaths
ais_target_state_flags & 262144 > 0 or # NumGoroutines
ais_target_state_flags & 1048576 > 0 # CertificateExpired
)
# Find nodes with warning conditions
ais_target_state_flags > 0 and on (node_id) (
ais_target_state_flags & 8 > 0 or # Rebalancing
ais_target_state_flags & 16 > 0 or # RebalanceInterrupted
ais_target_state_flags & 32 > 0 or # Resilvering
ais_target_state_flags & 64 > 0 or # ResilverInterrupted
ais_target_state_flags & 128 > 0 or # NodeRestarted
ais_target_state_flags & 32768 > 0 or # MaintenanceMode
ais_target_state_flags & 4096 > 0 or # LowCapacity
ais_target_state_flags & 8192 > 0 # LowMemory
)
Grafana Alerting
In Grafana, you can set up alerts based on these node state flags:
- Create a Grafana alert rule using the PromQL queries above
- Set appropriate thresholds and notification channels
- Configure different severity levels for red vs. warning conditions
Example Grafana alert rule for red alerts:
# Alert on critical node conditions
ais_target_state_flags{node_id=~"$node"} > 0 and (
ais_target_state_flags{node_id=~"$node"} & 8192 > 0 or
ais_target_state_flags{node_id=~"$node"} & 16384 > 0 or
ais_target_state_flags{node_id=~"$node"} & 262144 > 0
)
This alerting system provides comprehensive visibility into the operational state of your AIStore cluster and helps detect issues before they impact performance or availability.
StatsD Alternative
Important: StatsD support is deprecated and will likely be removed by the end of 2025. New deployments should use the native Prometheus integration described above.
StatsD Exporter for Prometheus
If specific requirements necessitate using StatsD, you can still integrate with Prometheus using its statsd_exporter component that translates StatsD metrics to Prometheus format on-the-fly.
Note: Native Prometheus integration is the preferred option. StatsD exporter should only be considered for deployments with special requirements.
Architecture with StatsD exporter:
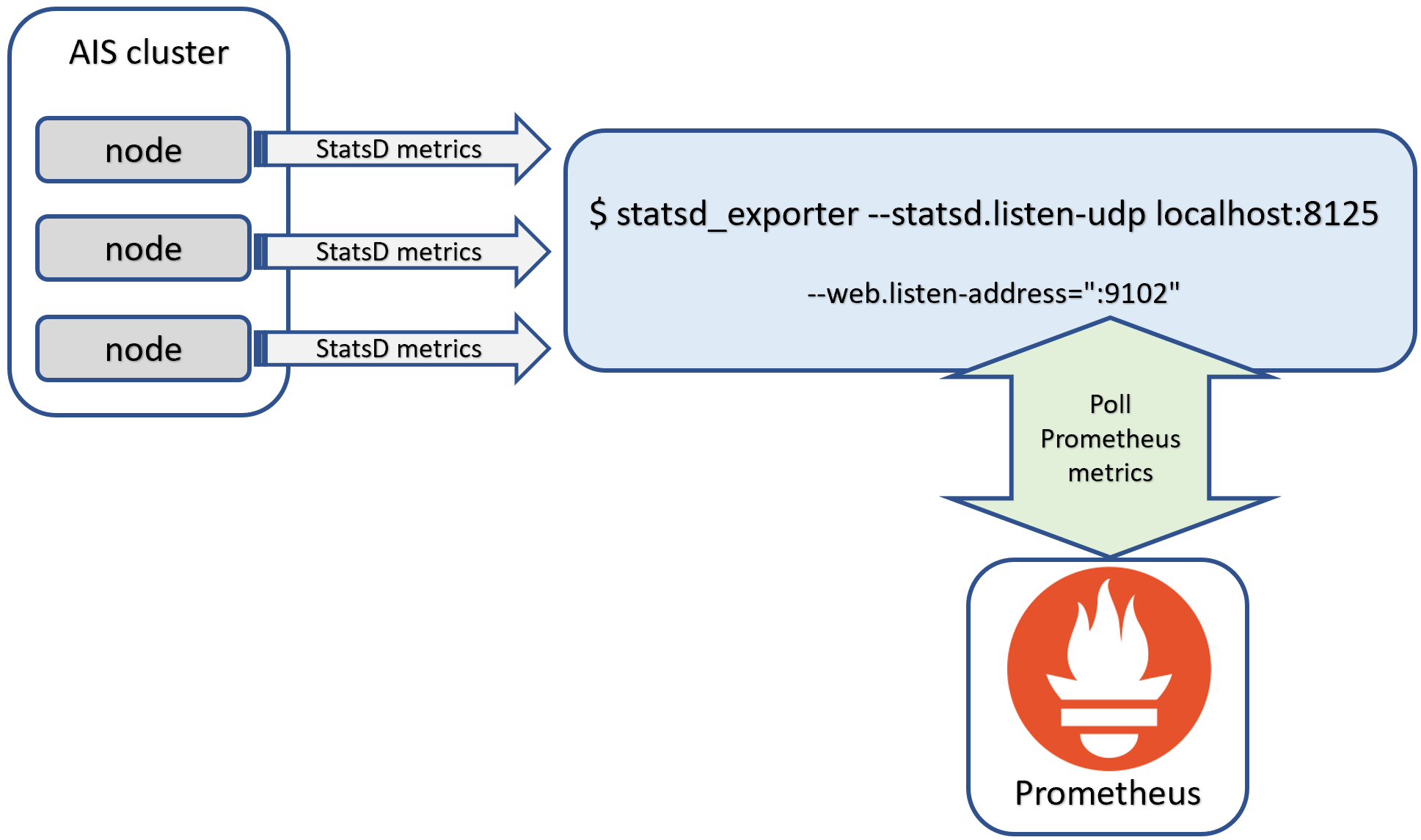
In this configuration:
- AIS nodes send StatsD metrics to a UDP endpoint
- The statsd_exporter receives these metrics and converts them to Prometheus format
- Prometheus scrapes the exporter’s HTTP endpoint
- Grafana queries Prometheus for visualization
Setup and Configuration
To deploy the StatsD exporter:
- Use the prebuilt container image, or
- Install from source:
$ go install github.com/prometheus/statsd_exporter@latest
For testing without Prometheus, run with debug logging:
$ statsd_exporter --statsd.listen-udp localhost:8125 --log.level debug
Example debug output:
level=info ts=2021-05-13T15:30:22.251Z caller=main.go:321 msg="Starting StatsD -> Prometheus Exporter" version="(version=, branch=, revision=)"
level=info ts=2021-05-13T15:30:22.251Z caller=main.go:322 msg="Build context" context="(go=go1.16.3, user=, date=)"
level=info ts=2021-05-13T15:30:22.251Z caller=main.go:361 msg="Accepting StatsD Traffic" udp=localhost:8125 tcp=:9125 unixgram=
level=info ts=2021-05-13T15:30:22.251Z caller=main.go:362 msg="Accepting Prometheus Requests" addr=:9102
level=debug ts=2021-05-13T15:30:27.811Z caller=listener.go:73 msg="Incoming line" proto=udp line=aistarget.pakftUgh.kalive.latency:1|ms
level=debug ts=2021-05-13T15:30:29.891Z caller=listener.go:73 msg="Incoming line" proto=udp line=aisproxy.qYyhpllR.pst.count:77|c
Finally, configure Prometheus to scrape the exporter’s metrics endpoint (default port 9102).
Default port configuration:
- StatsD UDP input: 8125
- Prometheus HTTP endpoint: 9102
To see all configuration options:
$ statsd_exporter --help
Best Practices
To maximize the value of AIStore’s Prometheus integration:
- Retention Planning: Configure appropriate retention periods in Prometheus based on your monitoring needs
- Dashboard Organization: Create dedicated Grafana dashboards for:
- Cluster overview (high-level health)
- Per-node performance
- Resource utilization
- Operation latencies
- Error analysis
- Alerting: Configure alerts for critical conditions:
- Node state red alerts (OOS, OOM, DiskFault, etc.)
- High error rates
- Disk utilization thresholds
- Performance degradation
- Metric Selection: Focus on key operational metrics for routine monitoring
- Collection Frequency: Balance scrape intervals for accuracy versus storage requirements
References
Related Documentation
| Document | Description |
|---|---|
| Overview | Introduction to AIS observability |
| CLI | Command-line monitoring tools |
| Logs | Log-based observability |
| Metrics Reference | Complete metrics catalog |
| Grafana | Visualizing AIS metrics with Grafana |
| Kubernetes | Working with Kubernetes monitoring stacks |